简易中英小词典iDict v1.0发布[Github开源]
时间:2018-01-28 ┊ 阅读:25,488 次 ┊ 标签: 开发 , 编程 , 设计
用wpf写了一个小词典,方便自己使用。
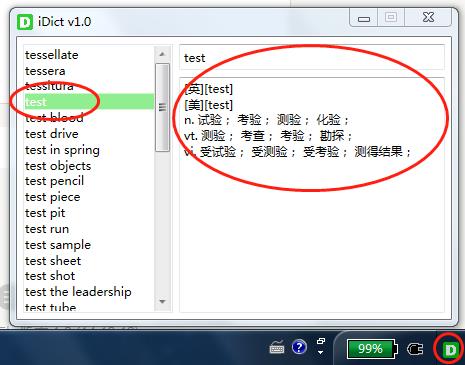
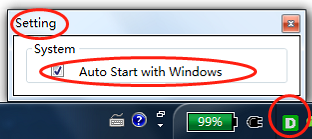
功能:
- 简易查词
- 最小化系统托盘
- 设置开机启动
词典是用python爬的iciba词库,基本够用了。
下面是python抓取词典源码,现学现用。python上手就是简单。
# -*- coding:utf-8 -*-
import re
import time
import codecs
import socket
import urllib.request
socket.setdefaulttimeout(60)
def grabDict(strWord):
strWord = strWord.strip()
strWordUrl = urllib.parse.quote(strWord)
boolRetry = True
while boolRetry:
try:
response = urllib.request.urlopen('http://open.iciba.com/huaci/dict.php?word=' + strWordUrl)
except:
print("time out happen, wait 5 seconds...")
time.sleep(5)
else:
boolRetry = False
pattern = re.compile(r'<[^>]+>', re.S)
regexStr = ".*?(<[\u4E00-\u9FA5]+>+)"
regexBlk = "\\+s"
for line in response:
strLine = line.decode('utf-8')
strLine = strLine.strip()
if strLine.startswith("dict.innerHTML"):
strLine = strLine.replace('\\"', '"')
strLine = strLine.replace('\\\'s', "'s")
# strLine = strLine.replace(strWord, '', 1)
strLine = strLine.replace("dict.innerHTML='", "")
matchStr = re.match(regexStr, strLine)
while matchStr:
matchWord = matchStr.group(1)
replaceWd = matchWord.replace('<', '〈')
replaceWd = replaceWd.replace('>', '〉')
strLine = strLine.replace(matchWord, replaceWd)
matchStr = re.match(regexStr, strLine)
strLine = strLine.replace("生词本</a>", "")
strLine = strLine.replace("详细释义</a>", "")
strLine = strLine.replace("';", "")
strLine = strLine.replace("]</strong>", "]~^~")
strLine = strLine.replace("</p>", "~^~")
strLine = strLine.replace("~^~;", ";")
strLine = strLine.strip()
strLine = pattern.sub('', strLine)
# strLine = ''.join(strLine.strip().split())
strLine = strLine.replace("\t", "").strip()
if strLine[len(strLine) - 3: len(strLine)] == '~^~':
strLine = strLine[0:len(strLine) - 3]
if strLine[0:3] == '~^~':
strLine = strLine[3:len(strLine)]
strLine = strLine.replace('〈', '<')
strLine = strLine.replace('〉', '>')
strLineTmp = ""
for strSec in strLine.strip().split("~^~"):
strLineTmp += strSec.strip() + "~^~"
if strLineTmp[len(strLineTmp) - 3: len(strLineTmp)] == '~^~':
strLine = strLineTmp[0:len(strLineTmp) - 3]
# strLine = strLine.replace(" ", "")
strLine = re.sub(r'\s+', ' ', strLine)
if strLine.startswith(strWord):
strLine = strLine.replace(strWord, '', 1)
strLine = strLine.strip()
return strLine
# strDict = grabDict("斯")
# print(strDict)
file_in = open('iDict.bin')
idx = 0
for linef in file_in:
strLineWord = linef.split('\t')[0].strip()
strUrlWord = grabDict(strLineWord)
if strUrlWord == "以上为百度翻译结果":
strLineFull = strLineWord + '\t' + linef.split('\t')[1].strip() + '\r\n'
else:
strLineFull = strLineWord + '\t' + strUrlWord + '\r\n'
file_ot = codecs.open('iDict_new.bin', 'a', 'utf-8')
file_ot.write(strLineFull)
file_ot.close()
idx += 1
print('we have grabbed ' + str(idx) + ' words.')
time.sleep(0.2)
file_in.close()
词典app是用C#编写,基于WPF视图,源码有空我放到github上。
文章评论
仅有1条评论
添加新评论
温馨提醒:如果您是第一次在本站留言,需要审核后才能显示哦!
相关文章

ValueError: Error getting directory
ssl证书过期了
明明自动renew的
然后看log已经好久没更新成功了
查半天是当前server不信任远程连接
只能自己改代码
报错:
21-12-17 13:01:11
Generate CSR...amkevin.csr
amkevin.csr generated.
/home/www...

Introduction to ILE RPG Activation Groups
Learn how activation groups can help your ILE RPG programs run more efficiently, how to specify the type of group to use, and closing and reclaimin...
![popup.js怎么和content.js通信?[JQuery]](/usr/uploads/2020/08/2743354336.png)
popup.js怎么和content.js通信?[JQuery]
这两天为了实现一个谷歌浏览器插件功能,研究了半天怎么让插件来改特定网页里的特定字段的值,而这个值又来自popup的网页预先设定,下一步实现动态加载,可以让更多组实现便利。
目的很简单,我们有一个list,需要填到网页的某个字段,当然是好几个,这些值是设定好的,网页系统我们没法改,input想...
![如何绕过登录抓取js动态加载网页数据[Python]](/usr/uploads/2018/11/2047962134.png)
如何绕过登录抓取js动态加载网页数据[Python]
今天经历了一翻折腾,把一个需要登录网站并js动态加载的数据一一给抓下来了。
首先,登录时有cookie,我们需要把cookie保存下来,用urllib2构建request时加入header信息,这时还多了一点,虚构了浏览器信息,让服务器以为是正常的浏览器发起的请求,这样可以绕过简单的反爬虫策略...
![终于用上了专业版的PyCharm含激活方法链接[Python]](/usr/uploads/2018/11/76196814.png)
自己终于可以用上干净的小词典了。